Architectural determinism: how web2 primitives encode centralization
I believe that the architecture of the modern web not only makes meaningful decentralization difficult but that it also structurally precludes it. As a consequence, seemingly "decentralized" systems built on top of modern web architecture inevitably collapse toward centralized intermediaries.

Note: This is a long form essay synthesizing my research and observations on web architecture and decentralization. I'm writing this primarily to organize my own thinking, but I'm sharing it publicly because I believe these ideas matter. I'm not claiming novel invention as most of these primitives have existed for years already. Also, I'm certainly not claiming to have all the answers. If you spot errors, faulty reasoning or have alternative perspectives, I genuinely want to hear them. This is exploratory work and not gospel, the conclusion contains a recap of the claims of this essay. Consider it an invitation to discussion.
Disclaimers: 80% my thoughts & ideas, 20% formatting & structure using gemini-2.5-pro. Title image by nano-banana.
I believe that the architecture of the modern web not only makes meaningful decentralization difficult but that it also structurally precludes it. As a consequence, seemingly "decentralized" systems built on top of modern web architecture inevitably collapse toward centralized intermediaries. I'm proposing an alternative set of primitives, or ways to think about the problem, that when properly composed, could make decentralization the path of least resistance rather than maximal pain.
Centralization gradient
Systems built on the modern web stack exhibit a consistent pattern: regardless of initial design intent, they converge toward centralized architectures over time, this almost feels like an architectural inevitability.
Every major protocol built on web foundations has followed this trajectory:
- Email was designed federated but now it's a Gmail/Outlook duopoly (>80% of users)
- Web hosting was designed distributed but today it's an AWS/GCP/Azure oligopoly (>60% of infrastructure)
- DNS was designed distributed but Cloudflare resolves >20% of web traffic
- etc...
I believe that these outcomes are not coincidental but that the architecture of these systems contain structural properties that make centralization energetically favorable.
Architectural centralization
A system is architecturally centralized if:
- Functioning requires third-party infrastructure that could observe, modify, or deny service
- Optimal performance or reliability creates pressure toward shared infrastructure
- Correctness relies on trusting entities outside the end-to-end path
- P2P (peer to peer) operation requires significantly more complexity than client-server
A system may be logically decentralized (example: federation) while remaining architecturally centralized if these properties hold.
Current modern web primitives
Location based addressing (DNS/IP)
The primary way of accessing the web today is by using what's called location based addressing. You click a link and you get a result: resources/things are identified by network location (https://domain.com/resource)
The request flow goes something like this (very roughly):
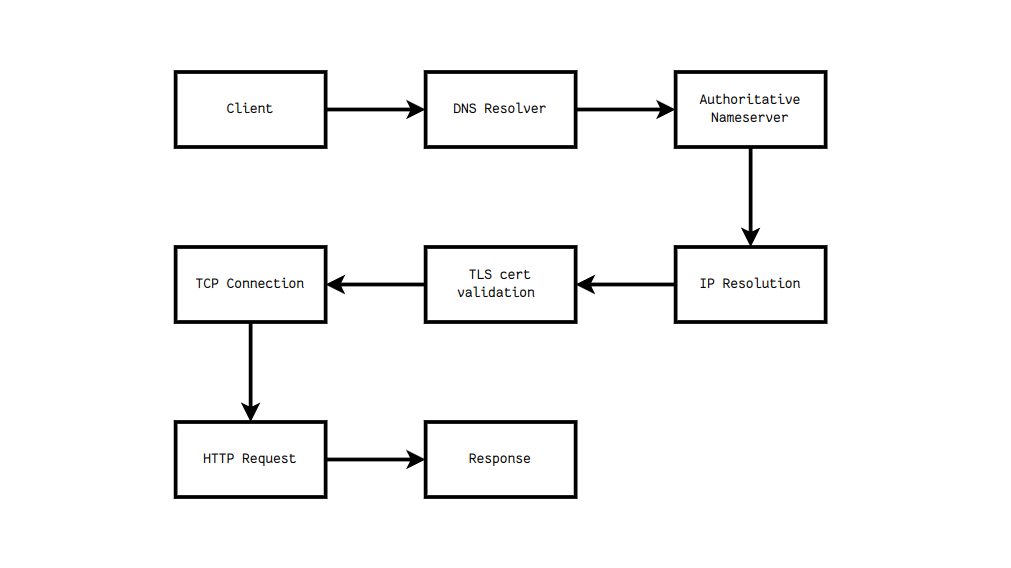
In this flow, there are 4+ mandatory intermediaries (DNS, CA, ISP, origin server) and more than 3 trust assumptions along the way (DNS hierarchy, CA system, server identity).
The consequences of this primitive:
- You cannot verify the content, a same URL can return different content. So no caching guarantees, no integrity verification, no offline operation. Additional layers can be used for mitigation (SRI, signatures, etc) but these are optional and never used in practice
- The server sending the response needs to be always on, if the origin is offline, the resource is unavailable. This means, 24/7 infrastructure costs, DDoS vulnerability, geographic latency, the mitigation of which is usually involving a CDN intermediary (read: more centralization)
- The performance is degraded by physical distance to the origin (geographic coupling). Users farther away have worse experience, so distributing the infrastructure becomes a way to make the experience better (thus, economies of scale favor large provider)
- Domain owners can change content, revoke access, track usage (censorship vector, surveillance vector)
These consequences combined posit that in location addressed systems, optimal resource availability requires resource replication across multiple locations. Replicating infrastructure exhibits economies of scale. Therefore, providers with larger infrastructure networks have structural cost advantages, creating convergent pressure toward consolidation.
Stateless Request/Response (HTTP)
Using HTTP, each request is independent, there is no session state in the protocol.
A HTTP exchange goes something like this (way simplified):
Request: Method + Headers + Body
Response: Status + Headers + Body
(so no persistent connection, no identity, no state)
The consequences of this primitive:
- Since applications need state and HTTP provides none, implementations usually leverage cookies, tokens, server-side sessions, resulting in applications usually implementing state management differently. This is a direct centralization vector because the session state is stored server-side, and thus the user bound to specific server pool.
- There is no identity layer in the protocol, so implementations leverage simple credentials, oauth flows, session tokens, which again, every application implements however they want. The usual mantra is "don't roll your own auth", so what devs do is they externalize it to identity providers. Another centralization vector.
- All requests are observable by network path, observers including ISPs, DNS resolvers, potential MITM... Of course a mitigation here is TLS encryption but as we'll see later, current ways of doing it aren't any better and introduce trust assumptions too.
So all that combined, it's safe to say that in stateless protocols, applications requiring state must implement state management at the application layer. Application-layer state management cannot provide end-to-end guarantees without trusted intermediaries. Therefore, stateless protocols force trust delegation to intermediaries.
In fact, the state must be stored somewhere, the options being: (1) client-side (tamperable), (2) server-side (requires trusting server), (3) distributed consensus (requires coordination protocol). Options (2) and (3) both require trusting entities beyond end points.
Interpreted execution (JavaScript)
Execution code is delivered as simple text and interpreted by browsers at runtime.
How JavaScript ends in your browser:
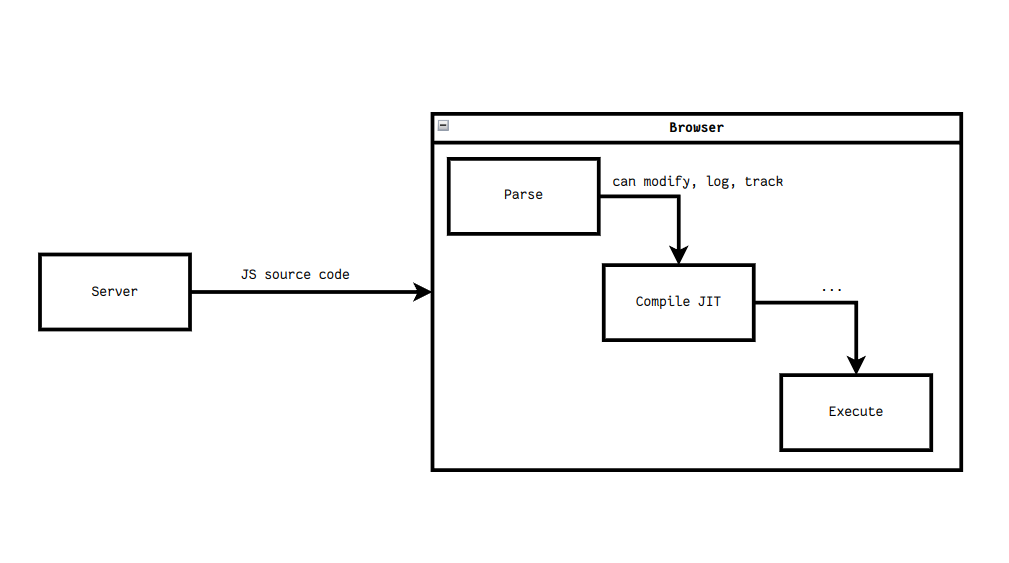
The consequence of this primitive are:
- Code execution is non-deterministic and hinges on browser version, JIT optimization, API availability, extensions etc
- Users cannot verify what code will execute because the source can be obfuscated, minified, or even completely different per request (note: even with SRI, you can't verify execution, only source)
- Browser vendor (third party) controls the runtime so they can deprecate APIs, add tracking, modify behavior (manifest V2 example), and there is absolutely no recourse
- Tabs share browser context, bringing with it cross-site tracking, fingerprinting etc...
Put together, in interpreted execution models, code verification is impossible without trusting the interpreter. The interpreter is provided by a third party (browser vendor). Therefore, code execution requires trusting a third party.
Certificate authority trust model (TLS/PKI)
This is the big one, trust is delegated to certificate authorities.
How it works:
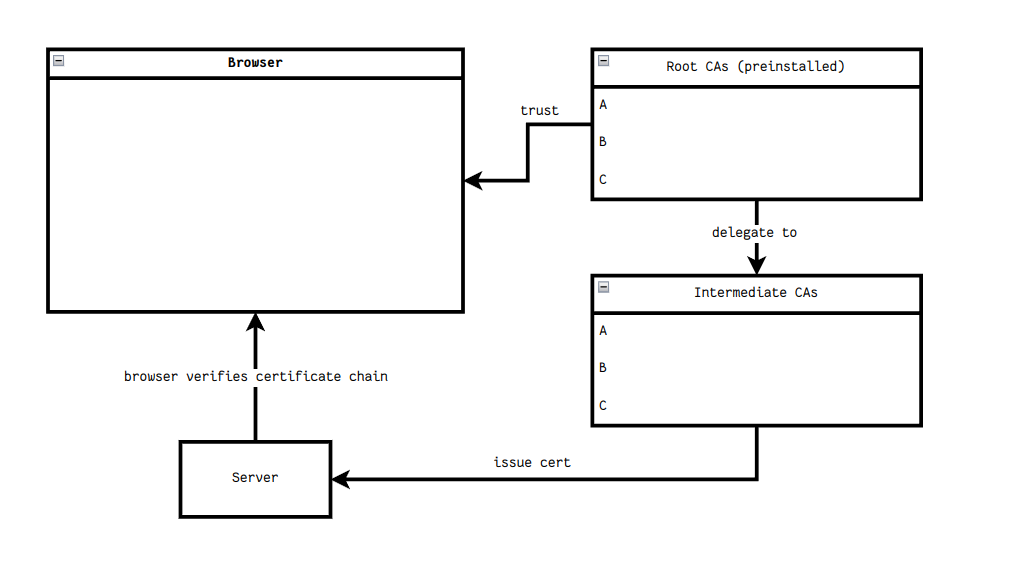
The consequence of this primitive are:
- All CAs must be trusted equally, meaning any CA can issue cert for any domain. Certificate transparency might mitigate this but doesn't solve it once and for all. There is a certain trust transitivity involved.
- CAs are subject to national jurisdiction, governments can compel CA to issue malicious certs. We've seen this happen.
- Certs rotate, there is no no identity persistence and it isn't possible to verify "same entity as last time". The result of this is usually that the identity is conflated with the domain name (controlled by the registrar) and not the cryptographic key ensuring the green lock in the browser
- Let's face it, ~3 CAs (or 2, if you think about it) handle the majority of web. A single CA compromise affects a massive swath.
Again put together, it's easy to say that in delegated trust models with transitive trust, security is bounded by the weakest link in the trust chain. As the number of trusted entities increases, the probability of voluntary or involuntary compromise approaches 1. For more on CAs please read this excellent (although tongue in cheek) article: https://michael.orlitzky.com/articles/lets_not_encrypt.xhtml
Why centralization is inevitable
The architectural primitives described above both enable centralization and make it structurally inevitable through four reinforcing mechanisms:
The intermediary trap
The web's architecture creates a recursive pattern where intermediaries are first convenient and then necessary. It starts with the primitives themselves: location addressing requires always-on infrastructure, stateless protocols demand session management, and performance requirements push toward geographic distribution.
Users naturally gravitate toward intermediaries offering the best performance and reliability. But here's where the trap springs: as usage concentrates on particular intermediaries, economies of scale kick in. Higher utilization means better cache hit rates for DNS resolvers, more efficient PoP (point of presence) utilization for CDNs, and improved spam filtering for email providers. These efficiency gains create a competitive moat that new entrants simply cannot breach. New entrants cannot match the unit economics of incumbents without first achieving comparable scale, which they cannot do without matching the performance that economies of scale provide. The market consolidates not because of anti competitive behavior but because the architecture makes any other outcome economically irrational.
Consider DNS resolvers: Google's 8.8.8.8 and Cloudflare's 1.1.1.1 collectively handle over 30% of global DNS traffic last I checked. They didn't capture this market through superior innovation alone though: recursive resolution fundamentally requires always-on infrastructure, and performance improves dramatically with scale as cache hit rates increase. Each query these services answer makes them marginally faster for the next query. A new entrant starting with zero queries has zero cached answers and must perform full recursive lookups for everything. They're structurally disadvantaged from day one. And here's the kicker: these entities see every domain every user visits, creating an observation point that enables both surveillance and control.
The same pattern plays out with CDNs. Geographic distribution is expensive: operating points of presence globally requires massive capital expenditure that only makes sense at scale. Fixed costs get amortized across more traffic, creating sublinear cost scaling. Cloudflare, AWS CloudFront, and Fastly don't just handle the majority of web traffic but they can modify, block, or surveil any content passing through their networks. Users don't choose this arrangement because they want surveillance but just because the alternative is unacceptably slow.
Email completed this same journey decades ago. SMTP's requirement for always-on servers with static IPs created a baseline infrastructure cost that favored consolidation, but spam filtering accelerated it dramatically. Effective spam detection improves with data scale because the more email you process, the better your models become. Same as with the CDNs, Gmail and Outlook don't just host email but they can read all of it, and they implement opaque rules for inbound and outbound mail that smaller providers must accommodate or face deliverability issues. Independent email servers are now so likely to be classified as spam that running your own email infrastructure is effectively infeasible for most use cases.
Performance gradient
Location addressed systems impose a hard physical constraint: latency is proportional to distance, bounded by the speed of light. This is just physics. Optimal performance therefore requires geographic distribution of infrastructure which is capital intensive and exhibits strong economies of scale.
Consider what actually happens during a web request. You pay for DNS lookup (20-120ms), TCP handshake (one round-trip time), TLS handshake (one or two RTTs depending on version), the HTTP request itself (another RTT), server processing time, and finally response transfer. For a user in New York accessing a server in Singapore, you're looking at about 15,000 km of distance. The physical lower bound for a round trip at light speed in fiber is roughly 150ms, but actual RTTs hit 200-250ms due to routing overhead. A typical page load requiring six round trips burns 1200-1500ms on network latency alone, before a single byte of content is processed.
The standard mitigation is deploying a CDN with global PoPs, but this costs at minimum $200/month for serious global coverage. Free CDN tiers exist, but they're either severely limited or subsidized by other revenue (usually surveillance-based advertising).
The economic implication is that only applications with direct revenue or subsidy can achieve acceptable global performance. Free or low revenue applications deliver inferior experiences, pushing developers toward ad-supported models that require user tracking which, of course, benefits from centralized data collection. The architecture makes surveillance capitalism the economically rational choice for anyone who wants their application to be fast.
Trust externalization spiral
When protocols lack essential primitives, applications must implement them at higher layers. This seems reasonable until you realize that application-layer implementation complexity creates strong economic pressure toward outsourcing, which concentrates users on a few providers, which grants those providers both data access and leverage, which creates lock-in. The spiral is self-reinforcing.
Authentication demonstrates this perfectly. HTTP has no identity primitive, so sites initially used username and password. Password reuse created security vulnerabilities, so password managers emerged. But password managers don't solve phishing, so two-factor authentication became necessary. 2FA improved security but added friction, so "Sign in with Google/Facebook/GitHub" emerged as the path of least resistance. Today, over 50% of sites support OAuth, and over 30% of users rely on federated identity. What seems like user convenience is actually structural: implementing robust authentication is sufficiently complex that outsourcing it is the rational choice for most developers.
But look at what happens during an OAuth flow. User clicks "Sign in with Google" then gets redirected to Google, and Google learns which site the user is visiting, when, and can correlate this with the user's identity. Google returns a token to the site asserting the user's identity, and the site trusts this assertion. Google can now see every login to every site using its OAuth, and can, if it chooses, impersonate any user. The site gains convenience and Google gains comprehensive surveillance of user behavior across the web.
None of this would be necessary if identity were a protocol primitive. With public key identity, the user signs a challenge, the site verifies the signature, and no third party is involved. But because HTTP lacks this primitive, we've built an entire industry around outsourced identity that extracts rent and surveillance rights in exchange for solving a problem that shouldn't exist.
I wrote about this in my earlier article here if you'd like to read a bit more about this:

Coordination tax
Perhaps the cruelest irony of web architecture is that building peer-to-peer systems on top of it is harder than building client-server systems, despite P2P being conceptually simpler (direct connection between peers). The architecture itself has been optimized for client-server patterns so thoroughly that P2P operation pays a massive coordination tax.
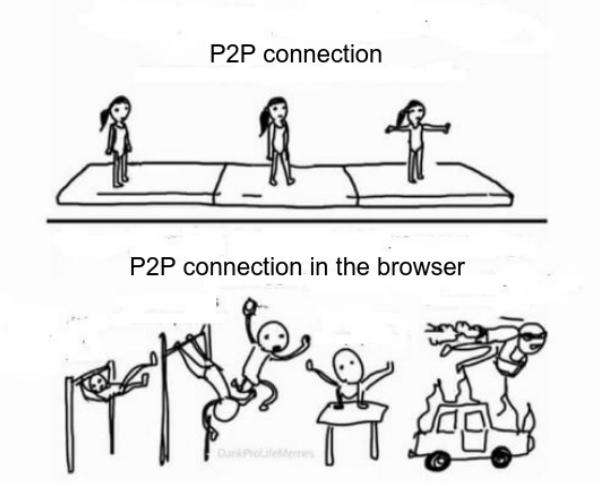
WebRTC demonstrates this tax explicitly. To establish a browser-based P2P connection, you need a STUN server (third party) to discover your public IP, a TURN server (third party) to relay traffic if NAT prevents direct connection, and a signaling server (third party) to exchange connection metadata. You then perform ICE negotiation, trying multiple connection paths to find one that works. Success rate for direct P2P is only about 70% due to NAT configurations, the remaining 30% requires TURN relay, which introduces the very intermediary you were trying to avoid. Oh, and this process adds 200-500ms of latency just for negotiation.
Think about that: connecting two browsers directly is harder and slower than connecting both browsers to a server, despite the direct path being shorter and requiring less infrastructure. This of course isn't WebRTC's fault though but rather the inevitable consequence of building P2P on an architecture optimized for client-server. NATs, firewalls, and ISP routing policies all assume client-server topology. P2P is swimming upstream while the architecture actively pushes water against it.
The fundamental problem is one of design philosophy:
- A web browser's job is to be a secure, sandboxed client. Its primary function is to fetch and display untrusted content from a server while protecting the user's machine from that content. It is designed for a client-server world. It requests, it does not serve.
- A P2P peer's job: to be a sovereign, first-class citizen of the network. It must be able to listen for incoming connections, store significant amounts of state, route data for others, and run persistently. It must be both a client and a server.
These two philosophies are in direct opposition. Trying to force a peer's job into a browser's sandbox leads to a series of crippling compromises.
The result is that developers rationally choose client-server not because it's technically superior but because the web makes it the path of least resistance. This is architectural determinism: the primitives shape the possibility space so thoroughly that alternatives become economically irrational even when technically feasible.
The above taken together, explains at least to me, why so many "decentralized" web3 projects end up with centralized components: they're fighting the architecture itself.
Alternative primitives
If centralization is structurally embedded in web primitives, the question becomes: what primitives would make decentralization structurally natural? I'm not claiming these are novel as many have existed for years or decades, but their composition creates a fundamentally different architectural possibility space.
Content addressing
Content addressing means resources are identified by cryptographic hash of their content rather than network location. The address format is simple: hash://algorithm:digest (e.g., ipfs://bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi). Verification is mathematical: hash(received_content) == address. Source is irrelevant as you can fetch from any peer because the hash guarantees content integrity.
This primitive has profound cryptographic properties. Hash collision implies content match, which means content is verifiable without trusting the source. Identical content has identical hash, which enables storage and bandwidth savings that scale with content reuse (reuse). Content can be fetched from untrusted sources safely, eliminating single points of failure and enabling resilience to server outages and censorship. Performance improves automatically because you can fetch from the geographically nearest peer rather than a specific origin.
The tradeoff is that no entity controls the hash space, so you cannot revoke access to content once published. This is a feature for censorship resistance but a bug for content moderation. Versioning requires higher-level abstractions like name services or blockchain registries.
Compared to location based addressing:
| Property | Location (URL) | Content (Hash) |
|---|---|---|
| Verification | Trust source | Mathematical proof |
| Availability | Source online | Any peer has copy |
| Performance | Distance to source | Distance to nearest peer |
| Caching | Time-limited | Permanent |
| Updates | Transparent | Explicit version change |
| Censorship resistance | Low | High |
In content-addressed systems, resource availability scales with demand. Under P2P architecture, high-demand resources get replicated more, improving both availability and performance. Popular content is cached by more peers, and availability approaches 1 as the number of peers increases: availability = 1 - ∏(1 - p_i) where p_i is the probability peer i is online.
Cryptographic identity
Entities are identified by public keys. The identity is the public key itself, example: Ed25519, 32 bytes. Authentication is accomplished by signing a challenge with the private key. Authorization is simply verifying the signature matches the public key.
The consequences of this architectural choice are interesting. "Registering" becomes a non-concept as there's no dependency on identity providers. Identity generation is unobservable and costs nothing since you just generate a keypair. The public key is the identity, and a signature proves knowledge of the corresponding private key. No CA needed, no third party involved. This works over any channel: signing HTTP requests, data structures, transactions, it's all the same and isn't tied to a specific protocol. Assertions about other keys enable complex authorization without central authority through delegation chains.
Compared to traditional authentication:
| Property | Username/Password | OAuth | Public Key |
|---|---|---|---|
| Registration | Required | Required | None |
| Trust dependency | Service provider | Identity provider | None |
| Portability | Per-service | Per-provider | Universal |
| Phishing vulnerability | High | Medium | None (no secrets sent) |
| Account recovery | Service-specific | Provider-specific | Backup key only |
In public key identity systems, authentication requires no third party and is unforgeable (assuming cryptographic hardness). This is at the same time more secure but also differently secure. The attack surface is local device security, not the security of identity providers and all network paths to them.
Deterministic execution
WebAssembly (WASM) provides a binary instruction format with specified semantics. It's a stack-based virtual machine with guaranteed memory safety, control-flow integrity, and determinism. Same input always produces same output, which means you can verify behavior without trust as the execution environment cannot subvert the computation.
WASM enforces principle of least privilege architecturally through capability based security. It's a compile target for many languages (C, C++, Rust, Go, and more), so you're not locked into JavaScript (and to me this is a huge benefit not to have to deal with that). The same binary runs identically on any browser, server, embedded device, desktop.
Write once, run anywhere, but for real this time.
Compared to JavaScript:
| Property | JavaScript | WASM |
|---|---|---|
| Determinism | No (JIT variations) | Yes (spec-defined) |
| Verification | Source only (if SRI used) | Binary hash |
| Performance | JIT-dependent | Near-native |
| Sandboxing | Same-origin policy | Capability-based |
| Language support | JavaScript only | Any language |
| Portability | Browser-dependent | Spec-guaranteed |
In deterministic execution environments, code behavior is verifiable by executing once and comparing the output hash. Verification complexity is O(1) in the number of verifiers. A content addressed WASM blob is guaranteed to be the thing you want to run.
Local-first data (CRDTs)
Conflict-free Replicated Data Types are data structures with commutative merge operations. Types include counters, registers, sets, sequences, and more. Operations happen locally with eventual synchronization, and concurrent updates are mathematically guaranteed to converge even without coordination.
Mutations can happen offline with no server dependency and syncing can occur later, asynchronously. Merges are automatic, and conflict resolution is built into the data structure. Any peer can sync with any peer without a central server.
Compared to client-server data:
| Property | Client-Server | CRDT |
|---|---|---|
| Offline writes | Impossible | Supported |
| Conflict resolution | Server-side logic | Mathematical merge |
| Sync topology | Star (all through server) | Arbitrary graph |
| Latency | RTT to server | Local (instant) |
| Dependencies | Server must be online | None |
In CRDT based systems, data availability is independent of server availability. Write availability approaches 100% as local storage reliability approaches 100%. You're no longer dependent on network connectivity for your application to function.
Light clients (verified computation)
Light clients enable resource-constrained devices to verify blockchain or distributed system state without downloading and processing the entire history. Instead of trusting a full node's responses, light clients verify cryptographic proofs that the response is correct. Here's roughly how it works:
- Full nodes maintain complete state and history
- Light clients download only block headers (small, fixed size)
- Merkle proofs allow verification that specific data is included in a block
- Header chain verification proves consensus without replaying all transactions
Compared to traditional clients:
| Property | Thick Client (Full Node) | Thin Client (RPC) | Light Client |
|---|---|---|---|
| Storage required | Full history (~TB) | None | Headers only (~MB) |
| Trust requirement | None | Trust RPC provider | None (verify proofs) |
| Query latency | Local (instant) | Network RTT | Network RTT + proof verification |
| Censorship resistance | High | Low (provider can lie) | High (can detect lies) |
| Resource cost | High | Low | Medium |
Light clients represent a crucial middle ground: they achieve the trust-minimization of full nodes with resource requirements closer to thin clients. For mobile devices and browsers, running a full node is impractical, but trusting an RPC provider reintroduces exactly the centralization we're trying to avoid.
In verified-computation models, security is decoupled from resource availability. A device with 1GB storage can have the same security guarantees as a data center with 100TB, because verification complexity is logarithmic in state size (via Merkle trees) while full validation is linear.
Composing primitives: Why this matters
Centralization pressure doesn't emerge from individual primitives but from how they compose. The same functionality implemented with different primitive combinations exhibits fundamentally different architectural properties.
Primitive composition determines architectural possibility and product destiny
Consider a standard web stack. You compose location addressing (DNS/IP), stateless protocol (HTTP), delegated trust (TLS/CA), and interpreted execution (JavaScript). Location addressing requires always-on servers. Stateless protocol requires session management, which means server state. Delegated trust requires trusting CAs. Interpreted execution requires trusting the browser vendor. The composition creates a system that requires trusting multiple third parties for basic functionality. There's no way around this given that it is baked into the primitive choices.
Now consider an alternative stack: content addressing (hash), cryptographic identity (pubkey), deterministic execution (WASM), and local-first data (CRDT). Content addressing allows fetching from anyone. Cryptographic identity allows authentication without third parties. Deterministic execution allows verification without trust. Local-first data allows operation without servers. The composition creates a system that functions without third parties. Not "can theoretically function" but "naturally functions". The absence of intermediaries is the default, not an exceptional mode.
Primitive choice determines the architectural possibility space. You cannot build a truly decentralized system on web primitives no matter how clever your application layer is. The primitives themselves encode centralization as a structural requirement.
Network effects run in opposite directions
In the web stack, network effects drive toward centralization. More users create more load, which requires bigger infrastructure, which has higher fixed costs, which creates economies of scale, which creates competitive advantage, which drives consolidation. It's a reinforcing cycle that naturally ends in oligopoly.
In a P2P stack with these primitives, network effects drive toward decentralization. More users mean more peers, which means better availability and better performance (shorter distance to nearest peer), which creates better user experience, which attracts more users. The reinforcing cycle makes the network more resilient and performant as it grows.
In content-addressed P2P systems, network performance improves monotonically with network size. This is the opposite of traditional systems where scale creates management burden. Scale creates resilience.
For instance, with 100 peers, average availability might be 98% but with 10,000 peers, it approaches 99.99%.
Economic structure: Zero marginal cost changes everything
The cost structures of these two stacks are radically different, and cost structure determines market structure.
Web stack costs:
Fixed costs include server infrastructure ($50-$10,000/month scaling with users), CDN ($20-$1,000/month scaling with bandwidth), DNS ($10-$100/month), TLS certificates ($0-$100/month), and monitoring/logging ($20-$500/month). Variable costs include bandwidth ($0.05-$0.15/GB), compute ($0.01-$0.10/hour), and storage ($0.02-$0.10/GB/month). Total: $100-$10,000+/month depending on scale.
For a web application, Cost(n users) = Fixed + (Variable × n). Scaling is linear to superlinear. You pay more as you grow, and someone has to pay those bills.
P2P stack costs:
Fixed costs are essentially just initial publication to a DHT ($0) or optionally an IPFS pinning service for reliability ($5-$50/month). Variable costs for bandwidth, compute, and storage are all $0 given they're provided by peers, run on user devices, and users store their own data. Total: $0-$50/month regardless of scale.
For a P2P application, Cost(n users) = Fixed. Scaling is constant. Your 10-millionth user costs the same as your first user: nothing.
The breakeven point is trivial: at any n > 0, P2P is cheaper. It's also an entire cost structure changes.
Consider value capture in a traditional SaaS application. User pays $100/month. AWS captures $30 for hosting. Cloudflare captures $10 for CDN. Auth0 captures $5 for authentication. Datadog captures $5 for monitoring. The developer receives $50. Intermediaries capture 50% of revenue, not through rent-seeking but through providing genuinely necessary infrastructure in a location-addressed, stateless, delegated-trust architecture.
In a P2P application, the user pays $100/month and the developer receives $100. Intermediaries capture 0% because there are no intermediaries, the architecture doesn't require them. Developers have 2x revenue at the same user price, or can charge 50% less for the same revenue. It's a different economic category.
One note: this applies to local-first P2P applications, not on-chain applications, since it's common and easy to incorrectly conflate "Web3" with "blockchain".
Market structure implications
Web architecture creates natural monopolies through a well understood mechanism. Infrastructure has high fixed costs. Marginal cost decreases with scale. The largest provider has the lowest unit cost. Smaller providers cannot compete on price. The market consolidates to oligopoly. Result: AWS, GCP, and Azure control over 67% of the cloud market. The market is working exactly as the architecture dictates.
P2P architecture eliminates economies of scale. There are no infrastructure fixed costs given users provide and ARE the infrastructure. Marginal cost is zero regardless of scale. Being large confers no cost advantage. Competition happens on quality and features, not on price. The market can remain diverse because there's no structural pressure toward consolidation.
In zero marginal-cost systems, market structure tends toward perfect competition rather than natural monopoly. This is why BitTorrent, after 20+ years, still has dozens of client implementations rather than one dominant provider. The architecture doesn't reward consolidation.
Security: attack surface is determined by trust dependencies
A web application's attack surface includes DNS poisoning (compromise resolver), TLS MITM (compromise any CA), server compromise (SQL injection, RCE, etc.), CDN compromise (modify cached content), browser compromise (XSS, CSRF, etc.), session hijacking (steal cookies/tokens), and supply chain attacks (compromised npm packages). You're trusting 5+ parties, and the attack surface is large and distributed.
A P2P application's attack surface includes private key theft (local device compromise), implementation bugs (in WASM runtime or application code), and social engineering (user signs malicious transaction). You're trusting 0 external parties, only cryptography and your local device. The attack surface is local only.
Quantitatively, if each attack vector has independent probability p of success, web application compromise probability is approximately 1 - (1-p)^7 ≈ 7p for small p, while P2P application compromise is approximately 1 - (1-p)^3 ≈ 3p. The web is roughly 2.3x more vulnerable, and that's a conservative estimate that assumes all attack vectors have equal probability.
Trust minimization
A system is trust-minimized if security relies only on cryptographic hardness assumptions, local device security (private key secrecy), and code correctness (verifiable via audit or formal methods).
The web stack requires trusting that the DNS hierarchy operates correctly, CAs issue certificates only to legitimate owners, browser vendors don't inject malicious code, servers provide correct content, and CDNs don't modify content in transit. These are institutional trust assumptions about organizations subject to compromise, coercion, error and of course, fiduciary duty.
The P2P stack requires trusting that hash functions are collision-resistant (cryptographic assumption), signature schemes are unforgeable (cryptographic assumption), WASM runtimes implement the specification correctly, and local devices protect private keys (user responsibility). These are fundamentally different kinds of trust.
Systems requiring trust in n independent parties have security bounded by the minimum security of those parties. If any party is compromised, the system is compromised. Trust-minimized systems have security bounded only by cryptographic assumptions and local device security. The attack surface is orders of magnitude smaller.
Bandwidth efficiency scales logarithmically
In location-addressed systems, serving a popular resource to n users costs the origin server n × size bandwidth. CDN caching reduces origin load but doesn't eliminate bandwidth costs. Total bandwidth is k × n × size where k is the cache miss rate.
In content-addressed P2P systems, the initial seed costs 1 × size. But peer sharing means each completed download immediately contributes upload capacity. Growth is geometric: 1, 2, 4, 8... parallel streams. In BitTorrent with 1 seed and 63 peers, distribution to all peers takes approximately 6 rounds (log₂(64)). The seed's total bandwidth usage is still 64 × size (same as server), but total network bandwidth is ~128 × size because peers also upload.
The critical difference: distribution time is O(log n) versus O(n). With 1,000 peers, client-server takes 1,000× longer than 1 peer; P2P takes ~10× longer. With 1,000,000 peers, the ratios are 1,000,000× versus ~20×. BitTorrent has empirically distributed exabytes of data with zero central infrastructure cost.
Note: these numbers assume sufficient peer adoption (heavy lifting assertion) Cold-start performance for unpopular content this is of course a real challenge.
Practical implications
Development complexity: different, not harder
Web application requirements:
Developer knowledge: HTML, CSS, JavaScript, React/Vue/Angular (frontend); Node.js/Python/Go, SQL, REST API design (backend); AWS/GCP, Docker, Kubernetes (infrastructure); monitoring, logging, scaling, security (operations).
Required services: compute (EC2/Cloud Run), database (RDS/Cloud SQL), CDN (CloudFront/Cloudflare), authentication (Auth0/Firebase), monitoring (Datadog/New Relic).
Deployment complexity is high: CI/CD pipelines, staging environments, production deploys, rollback procedures. Operational burden is continuous: 24/7 monitoring, security updates, scaling adjustments and i'm sure I'm missing a few.
P2P application requirements:
Developer knowledge: JavaScript/Wasm (frontend), CRDTs and local-first architecture (data), IPFS/libp2p basics (distribution).
Required services: optionally IPFS pinning ($5/month).
Deployment complexity is low: publish a hash, done. Operational burden is minimal given no servers to maintain and no scaling to manage.
The tradeoff is real though: P2P requires learning new paradigms (CRDTs aren't intuitive initially), but it eliminates operational complexity entirely. You're trading conceptual complexity for operational complexity. For many developers, this is a favorable trade as operational complexity never ends but conceptual complexity can be learned once.
User experience: faster and offline-capable
Web application first load:
DNS lookup (~30ms) + TLS handshake (~100ms) + HTML download (~50ms) + parse HTML (~20ms) + download CSS (~100ms) + download JS bundles (~500ms) + parse/execute JS (~200ms) + API calls (~200ms) = ~1200ms to interactive.
Subsequent loads with cached resources: ~300ms to interactive.
Offline: broken (unless PWA is implemented, which adds complexity).
P2P application first load:
DHT lookup (~125ms) + download WASM (~100ms) + instantiate WASM (~20ms) = ~245ms to interactive.
Subsequent loads from cache: ~20ms (instant).
Offline: works by default if data is cached locally via CRDT.
User-perceived difference: P2P loads ~5× faster and works offline without additional implementation effort. This is the inherent consequence of local-first data and content addressing.
Censorship resistance: built-in, not bolted-on
Web architecture has multiple censorship points: DNS blocking (national firewalls), IP blocking (ISP level), TLS interception (government MITM), server seizure (legal action), CDN compliance (ToS violations), and payment blocking (Visa/Mastercard). Effectiveness is high because there are multiple chokepoints. Workarounds like VPNs and Tor add complexity and can themselves be blocked.
P2P architecture has two potential censorship points: content hash blocking (requires deep packet inspection, expensive and incomplete) and P2P protocol blocking (also requires DPI, also expensive). Effectiveness is low because content is replicated across peers with no central server to seize. Workarounds aren't needed.
BitTorrent has proven this empirically! Despite 20+ years of legal pressure and attempts at blocking, it remains functional and widely used. The architecture itself is resistant to censorship in ways that application-layer solutions on web architecture can never achieve.
Conclusions
Core claims
- Current web architecture structurally precludes decentralization. Intermediaries are not incidental but architecturally necessary for functionality. Location addressing requires always-on servers, stateless protocols require session management, delegated trust requires trusting CAs, and interpreted execution requires trusting browser vendors.
- Cost structures create convergent pressure toward consolidation. Infrastructure with high fixed costs and decreasing marginal costs inevitably consolidates. P2P cost structures eliminate this pressure by making marginal cost zero regardless of scale.
- The web requires trusting multiple third parties. Alternative primitives reduce trust to cryptography and local devices. In delegated-trust systems, security is bounded by the weakest link. In trust-minimized systems, security is bounded by cryptographic hardness assumptions. The attack surface is orders of magnitude smaller.
- P2P can match or exceed web performance for popular content. Content addressing enables fetching from the nearest peer rather than specific origins. Bandwidth efficiency scales logarithmically versus linearly.
- Reducing trusted parties reduces attack surface. Each trusted party is a potential compromise point. Systems with fewer dependencies are more secure by construction, not by implementation quality.
- In systems where optimal performance requires infrastructure with economies of scale, market structure naturally converges toward oligopoly. This is just the market responding rationally to architectural incentives. AWS, GCP, and Azure dominance is a structural outcome and not an accident.
- In content-addressed P2P systems, resource availability and performance improve monotonically with network size. More users means more resilience, not more burden. Network effects run toward decentralization, not consolidation.
What this means
The modern web's centralization is not just a bug that can be fixed with better protocols on top of HTTP but a feature of the primitive composition. Federation, blockchain layers, and decentralized identifiers all face the same structural headwinds because they're built on primitives that encode centralization as a requirement.
True decentralization requires different primitives: content addressing instead of location addressing, cryptographic identity instead of delegated trust, light clients & deterministic execution instead of interpreted code, and local-first data instead of server-side state. These primitives compose into systems where decentralization is the path of least resistance, not maximum pain.
The economic implications are that zero-marginal-cost systems don't exhibit economies of scale, which eliminates the structural pressure toward consolidation. Markets tend toward perfect competition rather than natural monopoly. Developers capture 2× more value because intermediaries aren't architecturally necessary.
The timeline is uncertain tbh, but the direction is clear. I think technical barriers are falling: WASM support is widespread, IPFS has millions of users, and CRDTs are proven in production (Figma, Linear, ...). Economic incentives favor P2P for developers (lower costs) and users (better privacy, offline functionality). Social barriers remain, but every architectural transition faces adoption challenges.
The web won the last 30 years by making client-server the path of least resistance. P2P can win the next 30 by making decentralization the path of least resistance.
So perhaps the only way to build the real Web3 is to let Web2 go.
Open questions
These are genuinely open problems that need solutions:
- How to incentivize peers to provide storage/bandwidth without a payment layer? Altruism and reciprocity work at small scale (BitTorrent), but do they work for the entire web? Filecoin and Storj attempt to solve this with crypto payments, but that introduces complexity and volatility.
- How to prevent DHT pollution without centralized moderation? Anyone can publish anything to IPFS. How do you prevent spam, illegal content, or resource exhaustion attacks without a central authority deciding what's allowed?
- How to handle updates in content-addressed systems? IPNS and DNSLink provide mutable pointers to immutable content, but they reintroduce some centralization (DNS) or complexity (DHT-based naming). What's the right tradeoff?
- How do users discover applications in hash-addressed space? DNS provides human-readable names. Content addressing provides verification but not discovery. We need decentralized naming that's both human-friendly and secure (Namecoin, ENS, Handshake are attempts, each with tradeoffs).
- How do P2P systems interact with legal frameworks designed for client-server? Copyright law assumes identifiable servers. Data protection regulations (GDPR) assume controllable databases. How do you comply with "right to be forgotten" when content is replicated across thousands of peers?
If you want to work on solving these problems and shape the future of the human-centric web, as opposed to the corporate-web, join us: https://www.parity.io/careers