Imagine two piles of code, both free to use & modify, that roughly do the same thing. How do you pick between the two?
My personal rule is to always use the one that's simpler to run or get started with, even if it has less features than the other option. When it comes to software, particularly "free" software, I believe that simplicity has an economical value that is important to understand, quantify, and celebrate.
I'd go so far as to argue that free software's utility is inversely proportional to its operational complexity. In fact, there is free software and there is free software: when software requires excessive infrastructure, specialized tooling, custom API keys or opaque dependencies (10 Docker container for a UI), it ceases to be "free" in a practical sense. The hidden cost of using the software renders it inaccessible or a burden, de-facto undermining its purpose and hindering its chances of being improved and maintained, unless heavily subsidized.
Nerfed machinery, wrapped in the rhetoric of openness
The classical solution proposed, the cure to the symptom, is to have someone else manage the infrastructure for you: this effectively makes the "free but complicated" software a trojan horse for ecosystem lock-in, in other words: complicated free software is free... to rent.
If you're steadfast on wanting to own it, this "bloated" free software will raise the price of adoption and introduce costs that outweigh the software's nominal price of 0€: a lot more engineering effort, maintenance, work required to operate the thing. In short: more time spent on what the software needs to operate instead of time spent on getting what you want done. This simplicity debt is the hidden cost of future labor required to sustain needlessly complex "free" tools.
Complexity externalizes risk, simplicity distributes it.
"Industrial open-source software" often serves as marketing loss leaders for cloud vendors. Kubernetes, while "free", entrenches reliance on AWS/GCP/Azure and knowledge of complicated tools more often than not applied to the wrong problems. This creates a paradox: nominally libre tools become gatekept by infrastructure & knowledge costs.
Industrial free software has definitely its place, don't get me wrong, and is still leagues ahead of proprietary software. I'm a pragmatic and admit that not all problems can be solved with simple software, but the survival of non-simple software often depends on corporate welfare: it is a precarious model. Example: When XCorp abandons an open project, it dies (AngularJS, OpenOffice, Atom, etc). When a lone developer abandons ripgrep, someone else forks it in an afternoon.
For the developer ecosystem to thrive and for our tools to improve, we must incentivize tools that are economically free, not just technically free.
If it's not simple, it isn't really free software
On the other hand, simple free software has a few inherent properties that are quite desirable for things that should just work: sustainability, resilience to institutional decay and broad accessibility. The likelihood that someone runs a simple piece of software increases the likelihood of someone caring about that piece of software. It being simple gives it also higher chances to be maintained and continue evolving: simple software has faster iteration cycles. To me, "simple free software" does not mean just access to code, but first and foremost access to agency.
Richard Stallman’s distinction between "free software" (ethical imperative) and "open source" (practical benefits) applies here. Bloat is the "open source-ification" of freedom: a veneer of liberty masking operational bondage. Debates over what’s "too complex" and what is simple are endless, but practical testing cuts through the noise: A mail server requiring 6 docker containers? Pass. A link portfolio manager that just has 1 binary? Looks good to me. A static website requiring me to install the right Node version, install new packages and run a server: no thank you. You get the idea.
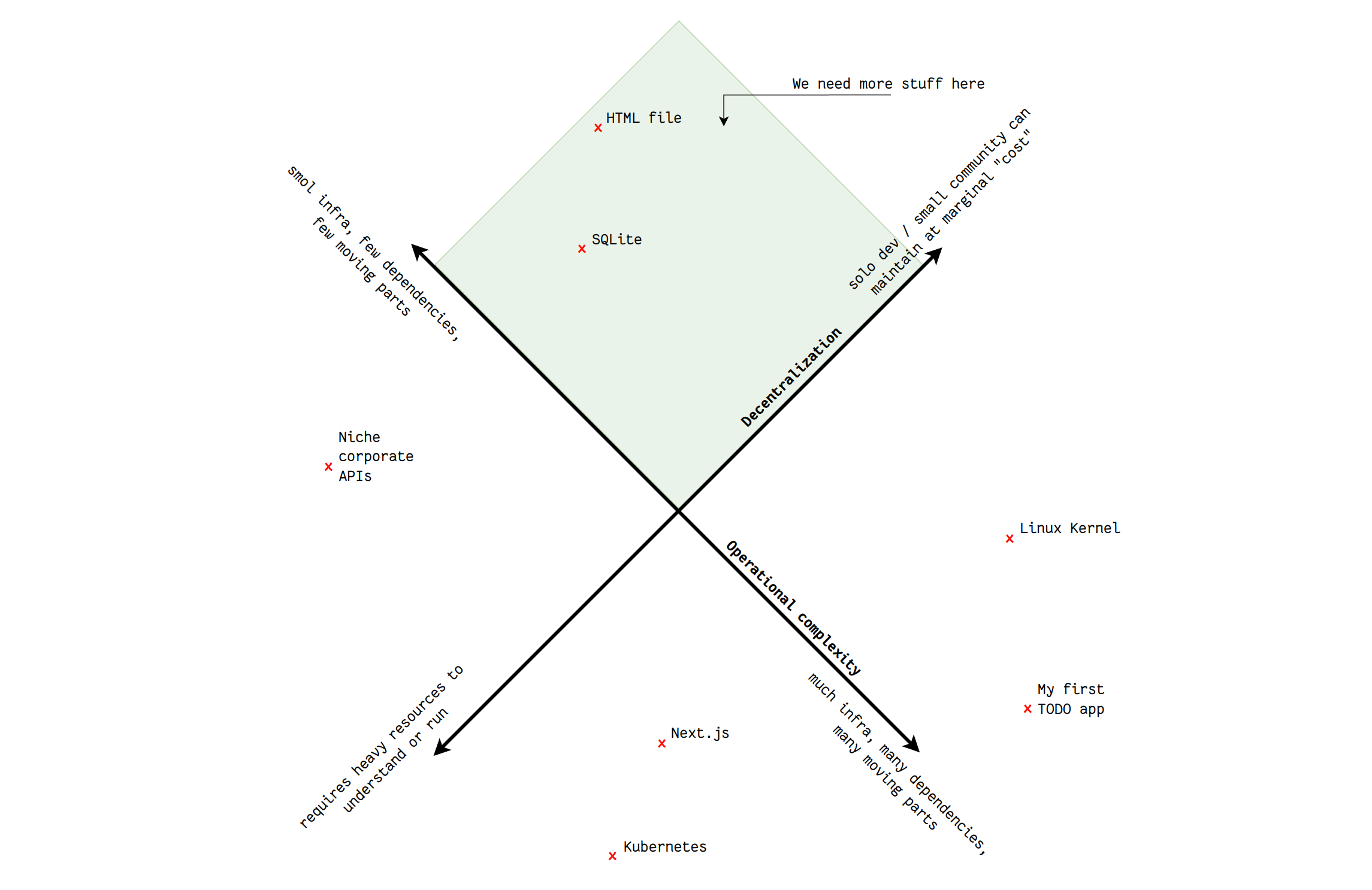
The same applies for software and systems I deploy and run. Complexity is a filter.
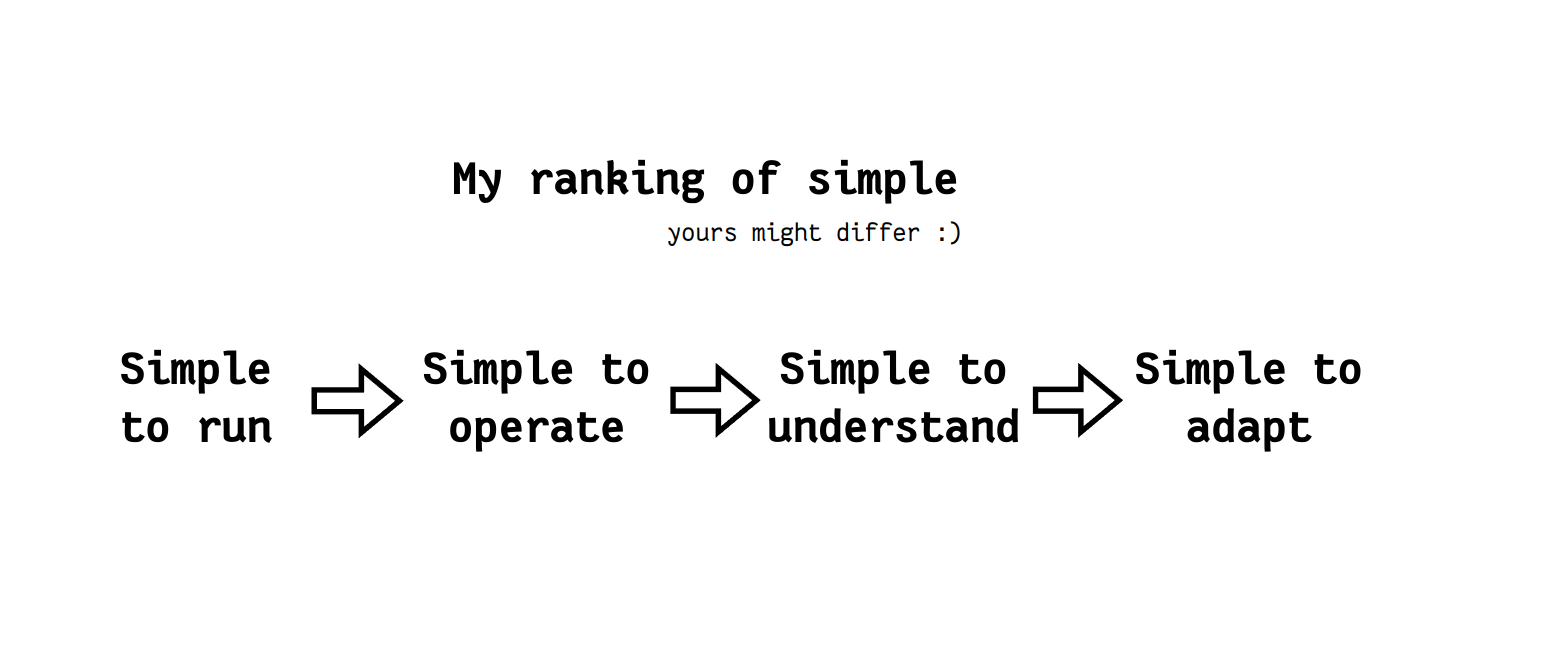
Of course there is a lot of nuance in the debate, and although I try to apply this point to any software I run and operate, I do not pretend to have the answer to how to build any simple version of software that I might use (case in point: how to make a simple OpenOffice?). For the software I use, I always favor things that I can tinker with in a simple way, or a way that I can remember how it works when I need it again 6 months from now.
Simplicity is a public good
All this to say that my general recommendation is to consider simplicity an economic necessity in the software you pick, especially given how easy it is to build software today. Nobody needs a CRUD app that requires downloading half the internet to run. Nobody needs a server when an html file can do.
A program that cannot be installed, understood, or modified by a single person is a house with invisible locks on every door. You may own the blueprint, but you’ll never live inside. This is not an abstract critique, it’s the daily reality for users trapped in ecosystems of orchestrated complexity.
The bottom line: Free software must prioritize agency over features, resilience over scale, and sovereignty over convenience.
The way forward is simple. Literally :)
Free software should be simple
Free software is better when it's simple to run, simple to understand, and simple to adapt. I argue that a lot of free software actually comes at a price that is not 0, and provide some hints and ideas for how I quantify "simple".