LLMs in the middle: Content aware client-side filtering
LLMs in the middle: Content aware client-side filtering using browser extensions and local large language models to filter content across multiple websites.
Lately I've been playing with large language models like many other developers out there. I became so interested with the technology that I even built myself a rig with a relatively strong GPU that I have sitting on my desk, serving multiple text, image & audio models.
While most of the focus of current developments goes in the direction of "generative" AI, meaning AI used to generate stuff, it can similarly be used to classify content under specific conditions.
One of the most interesting applications I've found of this, which prompted me to really commit to this "hobby", is to use language models to filter out content for me while I browse the web.
Browsing the web today
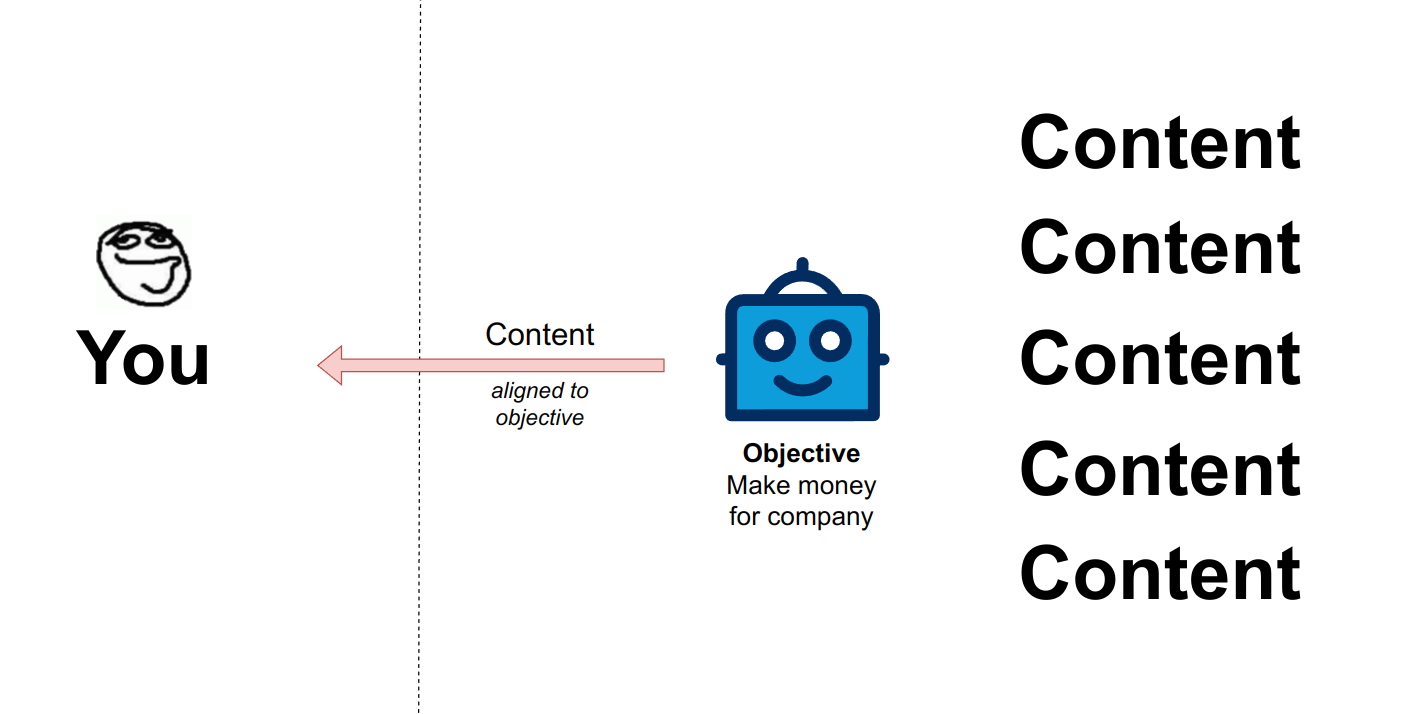
Most of the interactions on the web today are controlled and brokered by the entities hosting the content that others produce: YouTube, Twitter/X, TikTok etc. In the majority of cases, you get to see a piece of content either because an algorithm recommended it to you or if you searched for it explicitly.
These entities being for-profit companies, it isn't a surprise that these algorithms are designed for purposes that are largely to the benefit of the companies, amongst which keeping you engaged on the platform as much as possible might be very high up on the stack. The goal being to create an environment for effective advertising.
Right now the web looks like this:
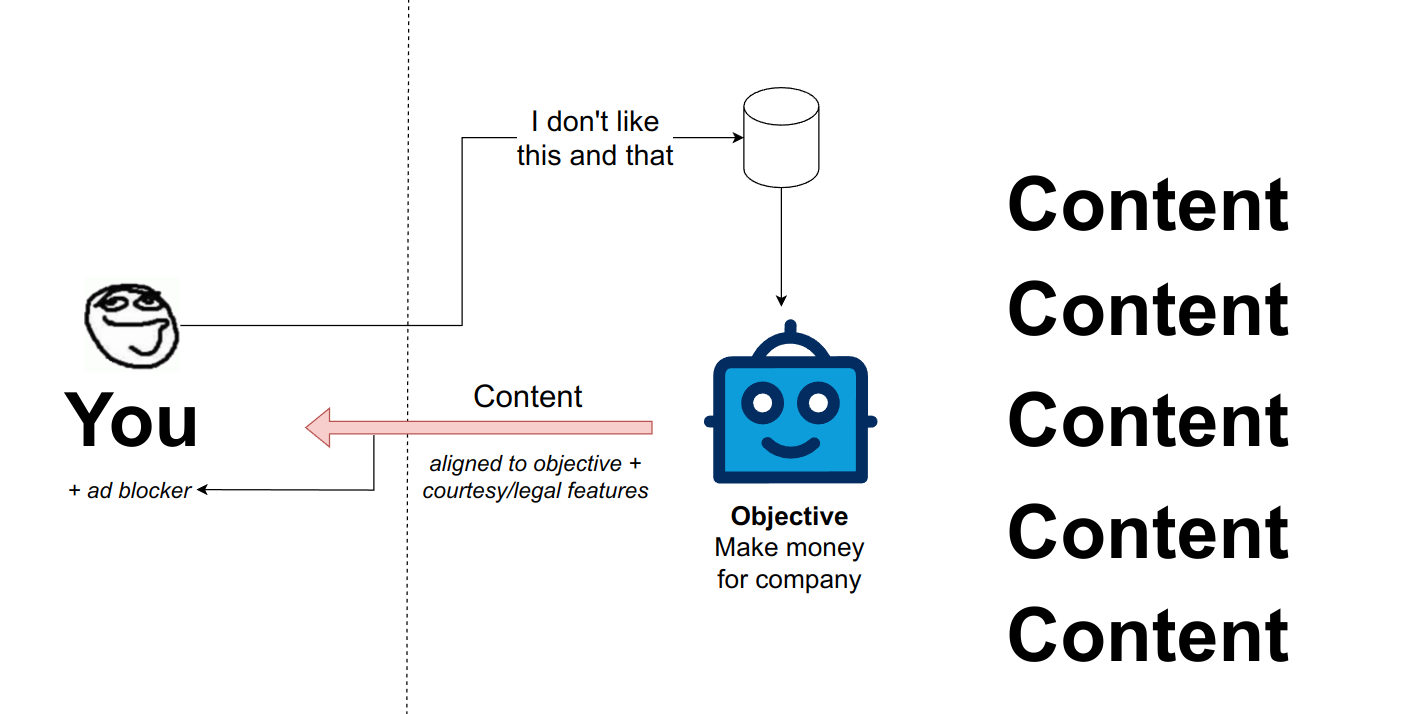
Some platforms allow you to filter out some things that you might not want to see, essentially by blocking or muting users you're not interested in seeing the content of or creating word filters that will not show you things if a specific word is present in them. The platforms don't have a unified way of doing this across different platforms and most importantly, you mostly cannot block ads.
To block ads, you will need to use third-party tools like ad-blockers or pay premium accounts here and there. These ad-blockers are deterministic and depend on the page structure, meaning, they block specific scripts & pieces of content depending on where they are on the website.
This is the best you can do:
Block block block.
However, providing platforms the data about whom and what you block, as well as showing that you're blocking ads, is another data point that is collected on their side and can be made use of and actioned on - as a data nerd I can't help but seeing data everywhere, these data points are very valuable.
So the best deal we're getting is this:
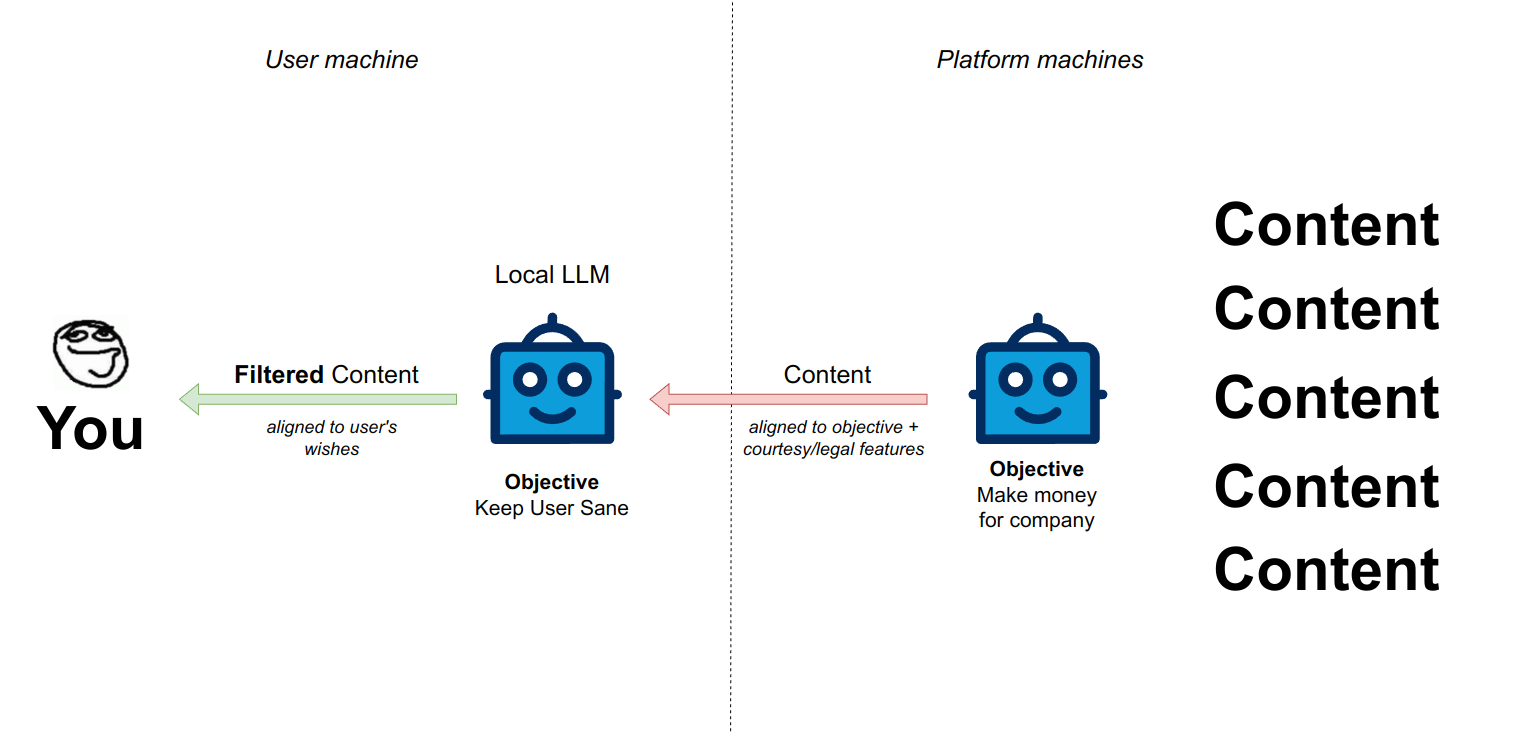
Using local large language models you can flip all of this on it's head:
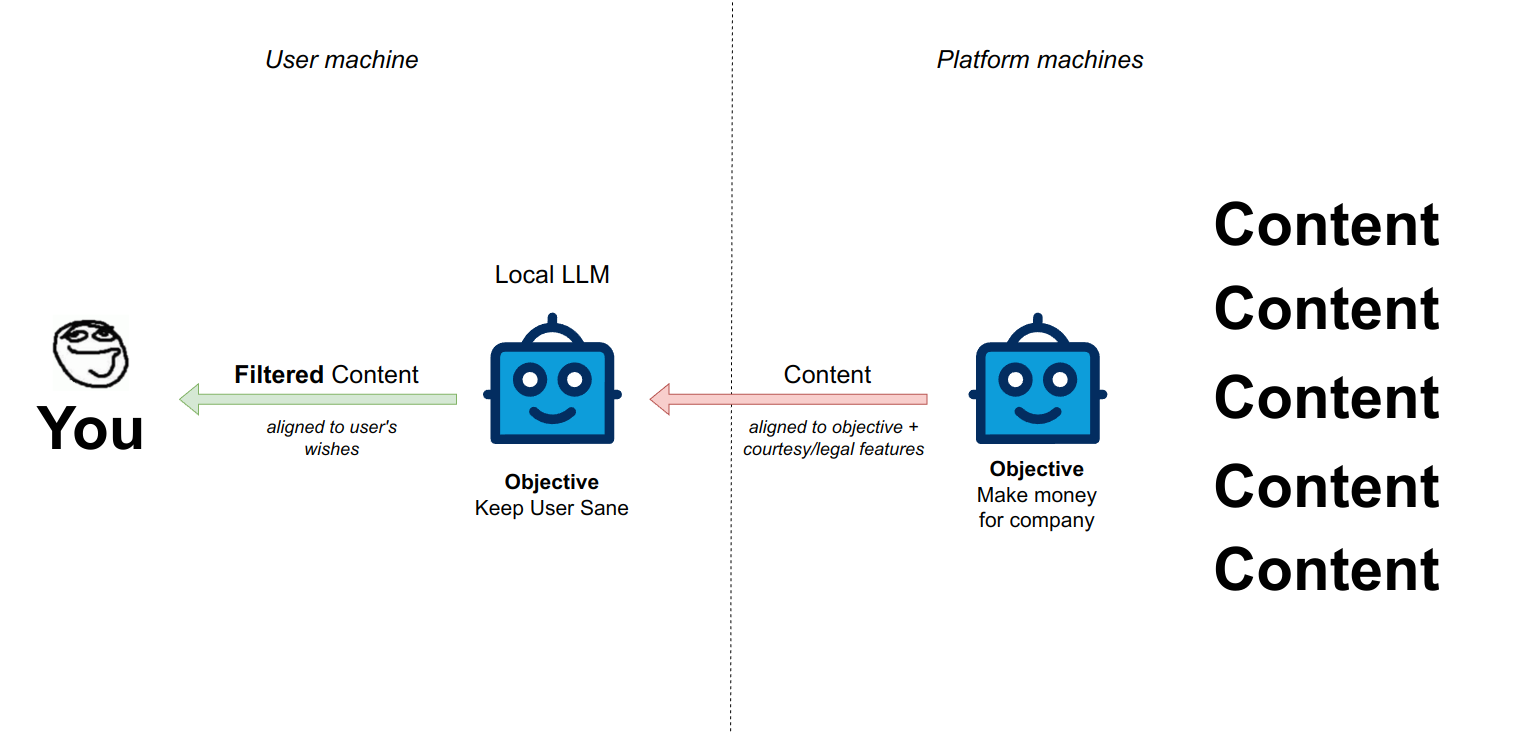
Sifting through the darkness - LLM style
For the South Park fans reading this, you might remember that one episode where Butters is tasked of editing Cartman's social media report: reading all the social media comments that Cartman is getting on his socials, and showing him only the positive ones. The episode is quite interesting, I won't spoil it for anyone who wants to watch it it's Season 19, Episode 5.
I created a similar bare bones, LLM based version of the service that Butters was providing not for my meager social media presence, but more for the content that I was recommended in my different feeds on multiple social media websites.
How it works is by combining rule based filters (user a, user b etc) and textual filters: passing the content of the "feed item" into an LLM and asking the LLM to classify it and then applying a rule based filter on the LLM's response. This thing is deployed as a browser extension that I've developed myself and that is interfacing with my LLM server (the machine I built myself)
Concretely, this is how it works:
- Input: A list of website and identifiers of single "feed items"
- Input: A local list of user filters (list of users & reasons for block, etc)
- For every feed item on each website in the active window
- Apply the rule filters
- Apply the LLM based filter (send content to LLM for classification + parse response)
- If we have a match, display a black box over the content
This is how it looks, roughly:
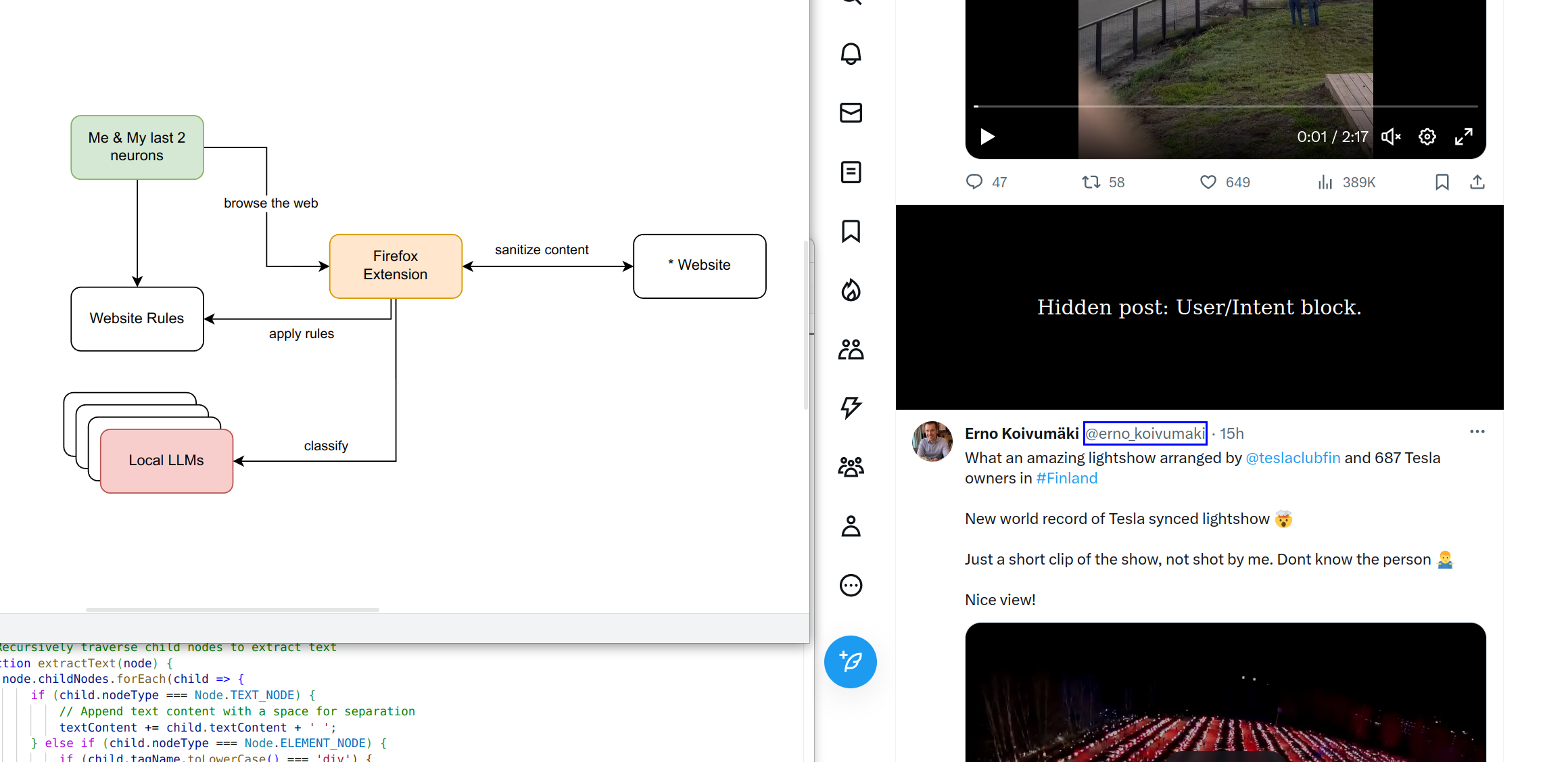
In it's current bare bones version, it's working relatively okay. It can be massively improved by adding contextual info like:
- how many times you saw this post,
- how many times this specific topic was presented to you
- etc
The cool thing with this is, that now YOU are the one collecting all this fancy-schmancy data that you'll be able to put to good use.
Now this is a browser extension and can be detected. But this type of thing can be developed without much overhead on the OS level as an application, restricting client side applications to detect any DOM changes - at which point it's game over.
Leveraging the obsession around "AI Alignment"
One of the hot topics in AI is called "AI Alignment", from my naïve understanding it's an attempt at making sure that an AI behaves and doesn't do bad things: like you'd train a dog not to bite (silly comparison, I know).
Incidentally, aligned models make for the best filters for these kind of content aware blockers, since they have already some bias towards not complying and categorizing something as "bad" right out of the box.
Where it might get tricky is when the AI's alignment and your personal alignment (beliefs?) are not aligned, in which case you can run the risk false positives, meaning not seeing pieces of content that would be actually interesting to you.
In this case, you might need to "fine tune" the model to your own beliefs and have it adapt to what you like and what you don't like.
Now, all of this is a small experiment I've put in place to keep my sanity and not leave my "brain space" at the whims of algorithms geared to get me and keep me engaged (addicted?) to this or that platform.
It's funny to see how people are afraid of AI taking over the world when much simpler algorithms already did, to some extent.
The future
As the models get smaller and more efficient, especially with the latest release of very performant 3B models from Stability AI, these sort of things will be absolutely trivial to implement and I expect them to be everywhere, even on mobile phones (which I didn't figure out how to do for now). I rather much delegate the decision of what I should or shouldn't see to an algorithm I personally control instead of an obscure algorithm tuned to "accaparate" and bank on my attention.
On a broader philosophical level, I like to think like this: Your brain is who you are. If you don't consciously shield it from what gets in it, you just might be the one being aligned, with ads, shitty content or worse.